Exploring Interrupt and Polling Mechanisms in DMA
In computer architecture, optimizing data transfer is essential for system performance. Direct Memory Access (DMA) controllers enable high-speed data movement between peripherals and memory without constant CPU involvement. A key decision in configuring DMA transfers is selecting the transfer flow sequence.
Polling Method DMA
Polling-based DMA requires the CPU to repeatedly check the DMA controller’s status to determine when a transfer is complete. The CPU polls the DMA controller at set intervals, usually via a status register or memory location. Once the transfer finishes, the CPU resumes its tasks.
Polling-based DMA is simple to implement since it does not require complex interrupt handling. It also offers determinism, as the CPU controls when polling occurs, which benefits real-time systems. Additionally, it incurs lower overhead than interrupts because it avoids context switching.
However, polling keeps the CPU occupied, reducing availability for other tasks. In systems with frequent DMA operations, this can hurt performance. Polling also introduces latency, as the CPU may not immediately detect completed transfers, delaying subsequent tasks. Infrequent or unpredictable data transfers further waste CPU cycles, leading to inefficiency.
Interrupt – Driven DMA
Interrupt-driven DMA notifies the CPU via an interrupt request (IRQ) when a transfer is complete. The CPU pauses its current task to handle the interrupt.
This method reduces CPU overhead, allowing it to handle other tasks while waiting for data transfers. It also minimizes latency by immediately signaling the CPU upon completion, making it ideal for time-sensitive applications. Additionally, by decoupling the CPU from data transfers, it enhances multitasking and system flexibility.
However, interrupt-driven DMA requires hardware support for interrupt handling, increasing system complexity and cost. In systems with multiple interrupts, priority inversion may occur if a low-priority DMA transfer delays higher-priority tasks. Handling interrupts also incurs overhead from context switching, which can affect performance in high-frequency scenarios.

Comparison
When comparing the two methods, interrupt-driven DMA generally offers better performance and responsiveness compared to polling-based DMA, especially in systems with high data transfer rates or stringent latency requirements. Polling-based DMA is simpler to implement but may not be suitable for high-performance or real-time systems. Interrupt-driven DMA, while more complex, offers greater flexibility and efficiency.
In terms of resource utilization, polling-based DMA ties up the CPU, leading to inefficient resource utilization, whereas interrupt-driven DMA allows the CPU to perform other tasks concurrently, improving overall system efficiency.
Both polling-based DMA and interrupt-driven DMA have their advantages and disadvantages, making them suitable for different use cases. The choice between these methods depends on the specific requirements of the system and the trade-offs between simplicity, performance, and flexibility.
Buffer Size
The buffer size plays a crucial role in DMA (Direct Memory Access) transfers as it directly impacts the efficiency, performance, and resource utilization of the system. The buffer size determines the amount of data that can be transferred in each DMA operation before the CPU is involved.
A larger buffer size allows for fewer DMA transactions, reducing the overhead associated with DMA setup and teardown, and maximizing the throughput of the transfer. However, an excessively large buffer size can lead to wasted memory resources and increased latency if the DMA controller must wait for the buffer to fill before initiating a transfer.
Conversely, a smaller buffer size may result in more frequent DMA transactions, potentially increasing CPU overhead and reducing overall system performance. Therefore, selecting an optimal buffer size is essential to achieve efficient data transfer, minimize latency, and maximize system throughput in DMA-based applications.
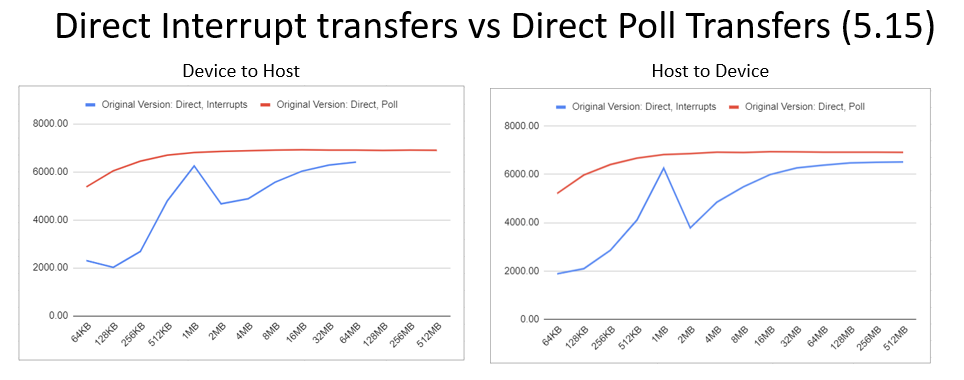
In a research we performed <Link>, we found that each DMA method has its sweet spot before it stagnates or gets to the point of diminishing performance. The x-axis shows the buffer size and the y-axis shows the transfer rate in MB/sec. The transfers were tested for 10 seconds each.