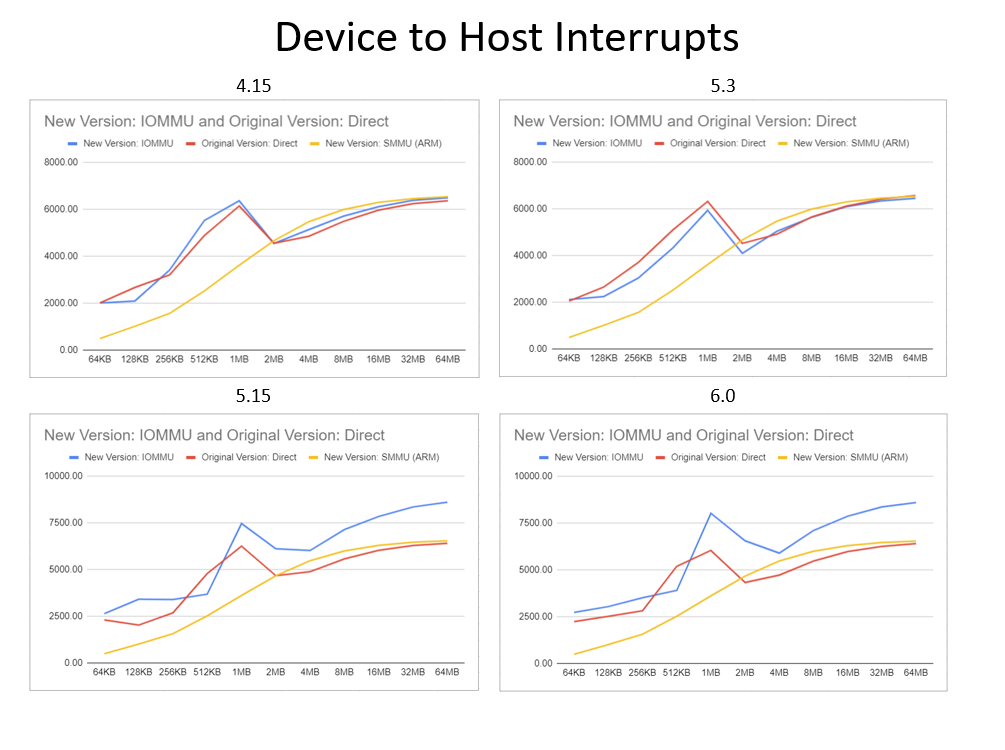
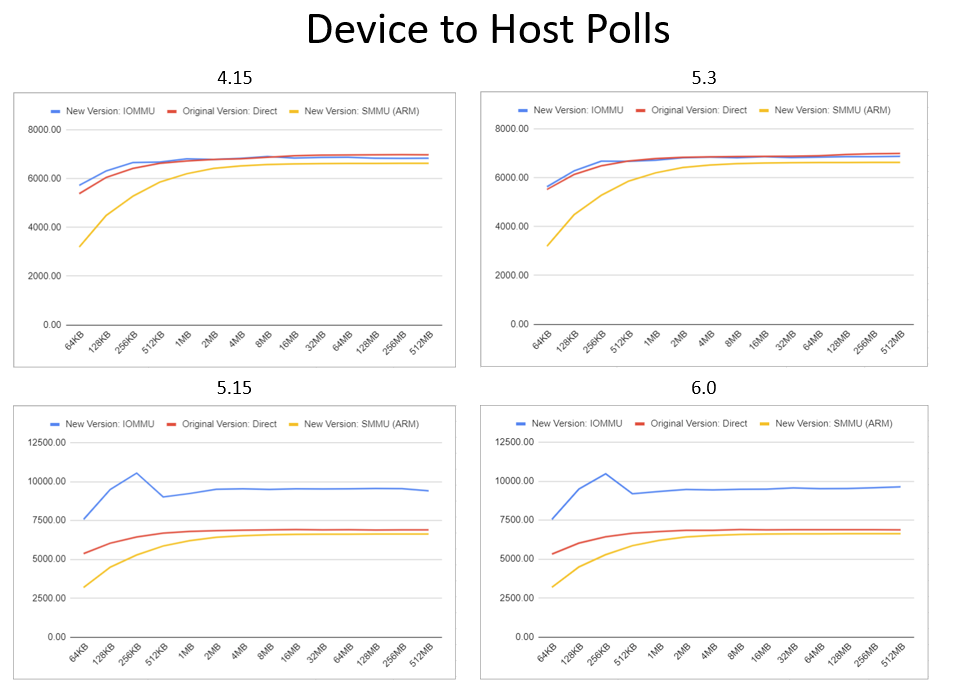
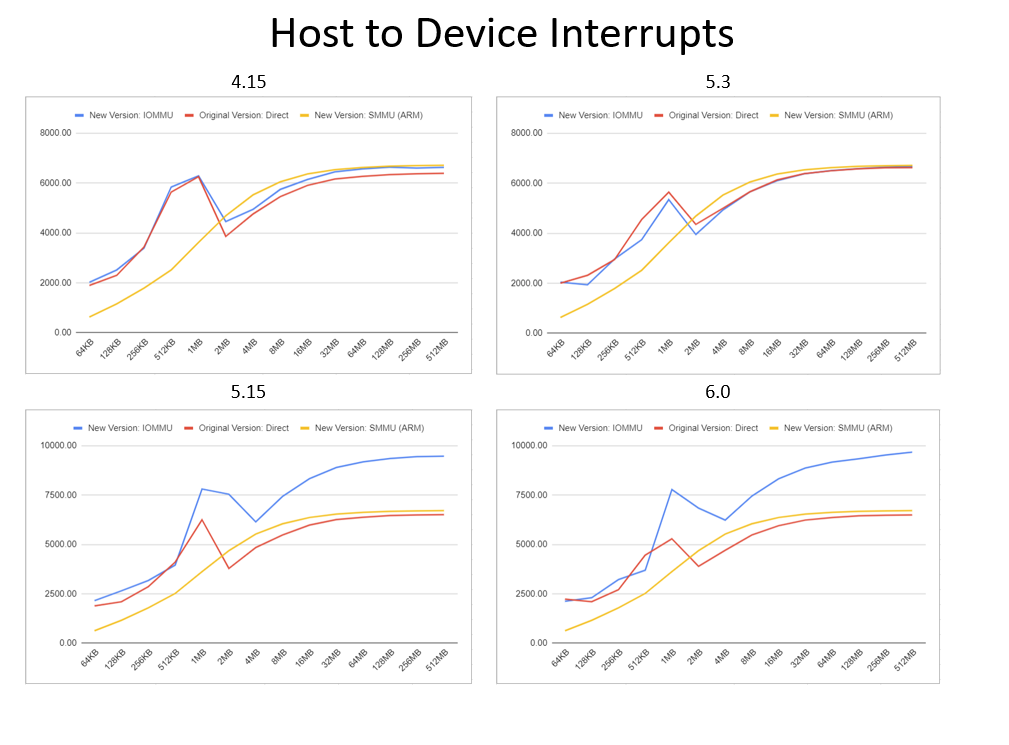
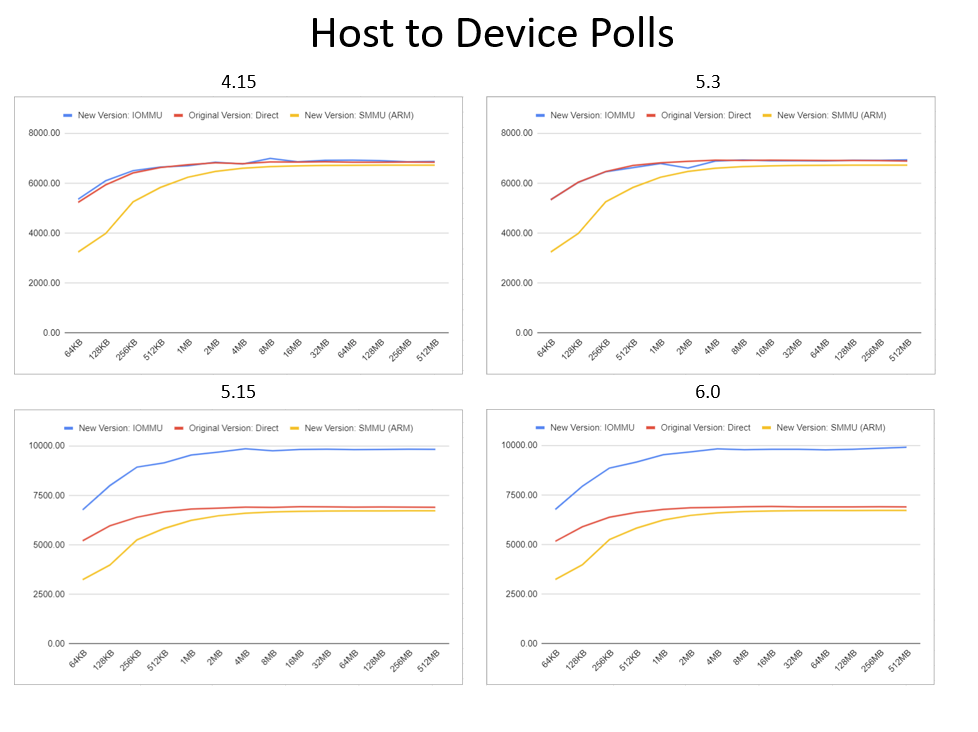
Simplifying PCI Diagnostics (Device Testing and Debugging with PCI Diag)
Simplifying PCI Diagnostics: Device Testing and Debugging with PCI Diag
The PCI Diagnostic Tool (PCI Diag) is a powerful utility designed to help developers test, debug, and interact with PCI devices efficiently. This fully functional sample application allows users to access and control devices without modifications, making it an essential resource for driver development and troubleshooting.
Supporting both Windows and Linux, PCI Diag facilitates seamless device detection, interrupt handling, and memory management. Additionally, it provides key insights into PCI configuration, Inter-Process Communication (IPC), and Direct Memory Access (DMA), helping developers validate and optimize their implementations. In this guide, we will explore its core features and functionalities in detail.
PCI Diagnostic Tools: Functions for PCI Device Interaction
Device Access & INF Files
- Windows: Accessing PCI devices requires an INF file. The WinDriver suite includes the DriverWizard utility, which simplifies INF file creation. This tool detects device information, defines interrupt details, and generates skeletal diagnostics code, including interrupt routines.
- Linux: INF files are not required, streamlining device access.
Debugging & Code Generation
- PCI Diag assists developers in understanding API usage, interrupt handling, and licensing requirements.
- It helps identify whether issues stem from the device or the code, reducing debugging time.
- Sample code is available in C, .NET, Python, Java, and PowerShell, facilitating quick integration into various workflows.
Live Demo & Core Functionalities of PCI Diagnostics
Scanning PCI Devices
- The tool scans PCI devices and retrieves crucial details such as vendor ID, device ID, memory addresses, and interrupt settings.
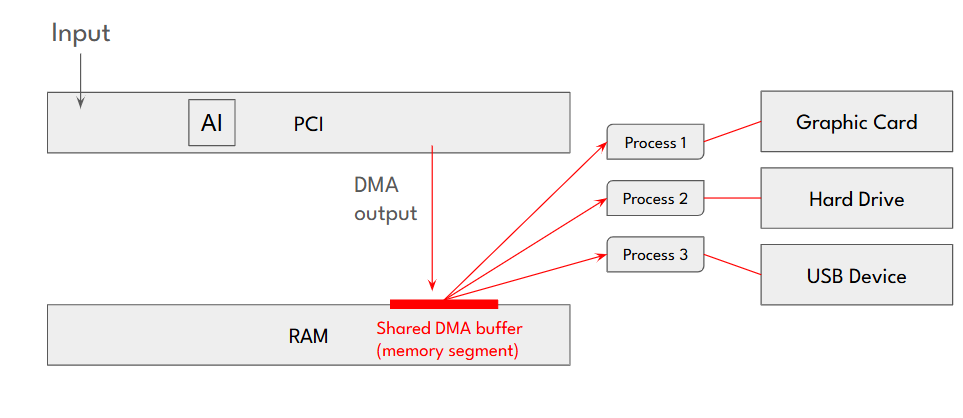
Inter-Process Communication (IPC)
- PCI Diag enables multiple applications to share data from a PCI device, simplifying IPC management and improving performance.
Reading & Writing to PCI Configuration Space
- Users can view configuration registers and read or write offsets directly within PCI Diag, eliminating the need for additional coding.
- This feature makes device configuration adjustments quick and straightforward.
Checking Device Capabilities
- PCI Diag identifies the types of interrupts a device supports, along with other key capabilities, helping developers optimize performance and ensure compatibility.
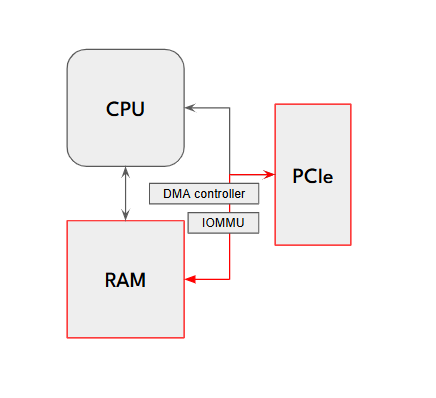
Memory & Buffer Management
- Developers can allocate and free shared buffers for efficient inter-process communication.
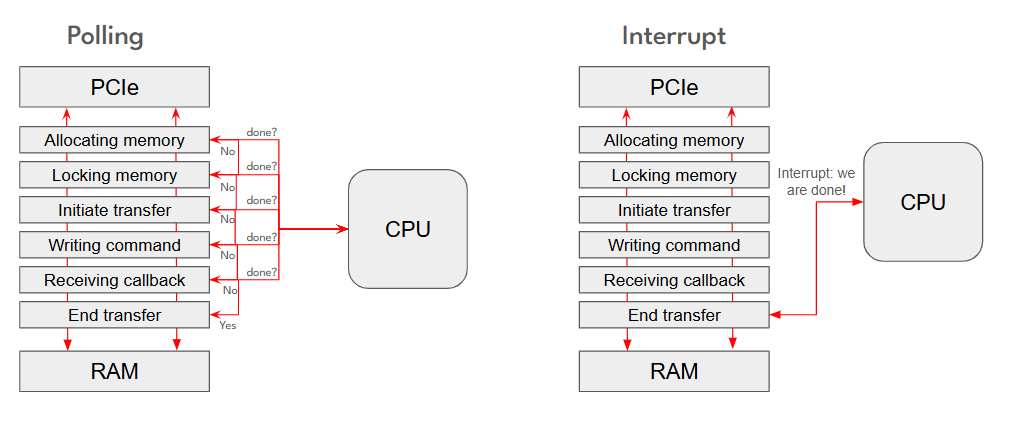
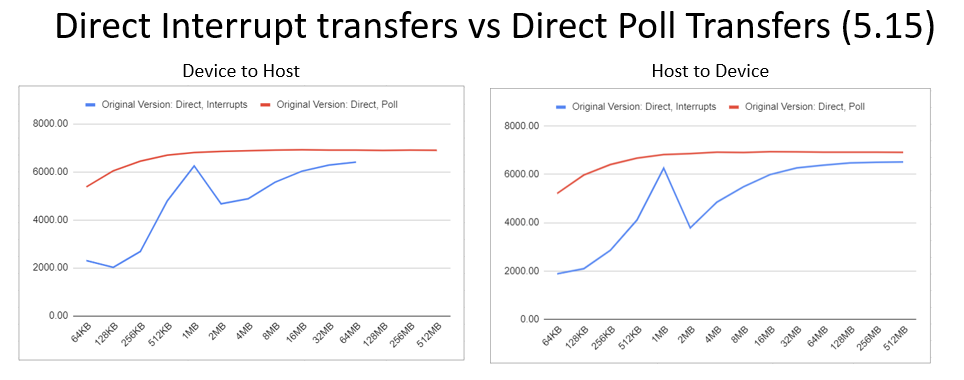
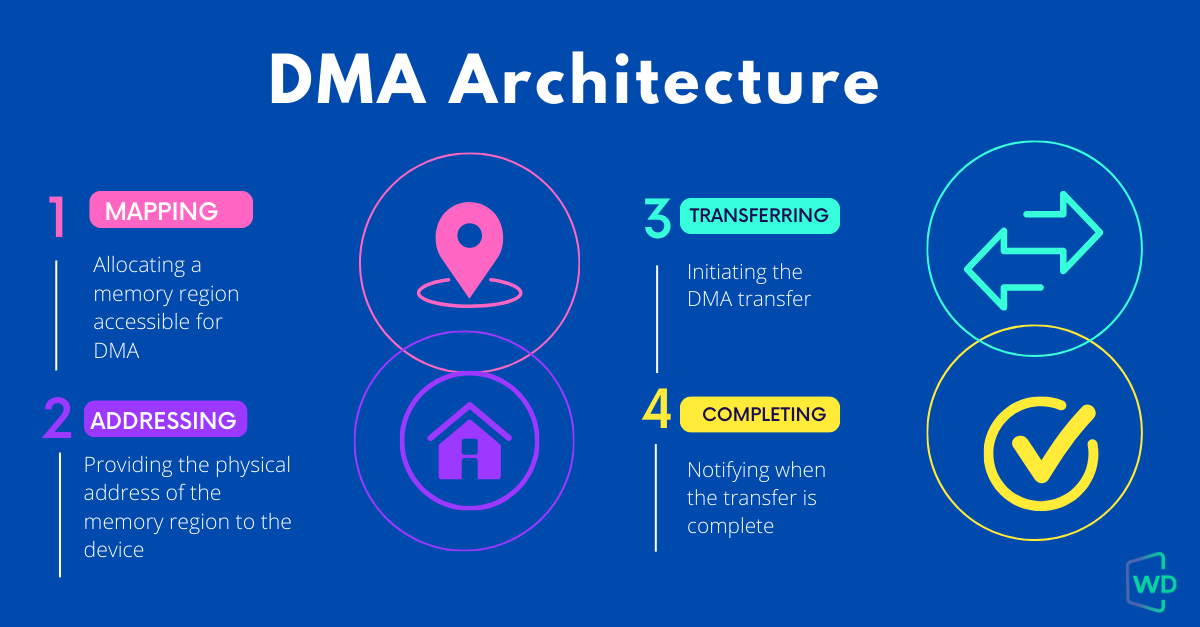
- The tool also supports DMA operations and scatter-gather memory allocation, ensuring smooth and efficient data transfers.
Troubleshooting PCI Diag Issues
PCI Diag is designed to work reliably across various PCs and PCI devices, making it an invaluable tool for testing and debugging.
Download WinDriver for free, and enjoy our 30-day trial.